AI in real life: Using LLMs on Microsoft Learn
Abstract
Enthusiasm for AI tools, especially large language models like ChatGPT, is everywhere, but what does it actually look like to deliver large-scale user-facing experiences using these tools? Clearly they’re powerful, but what do they need to make them work reliably and at scale?
In this session, Sarah provides a perspective on some of the information architecture and user experience infrastructure organizations need to effectively leverage AI. She also shares three AI experiences currently live on Microsoft Learn:
- An interactive assistant that helps users post high-quality questions to a community forum
- A tool that dynamically creates learning plans based on goals the user shares
- A training assistant that clarifies, defines, and guides learners while they study
Through lessons learned shipping these experiences over the last two years, UXers, IAs, and PMs will come away with a better sense of what they might need to make these hyped-up technologies work in real life.
Deck
 Hello! Today I’m going to share what I feel like I have learned, being part of a PM team shipping generative AI experiences for the past few years. Like many of us, ML and AI weren’t particularly part of my training, and I didn’t particularly expect it to become part of my working life, but here it is. And now, the product I work on, Microsoft’s documentation, training, and credential website, is shipping AI experiences regularly.
Hello! Today I’m going to share what I feel like I have learned, being part of a PM team shipping generative AI experiences for the past few years. Like many of us, ML and AI weren’t particularly part of my training, and I didn’t particularly expect it to become part of my working life, but here it is. And now, the product I work on, Microsoft’s documentation, training, and credential website, is shipping AI experiences regularly.
I’m far from the only one on my team doing this, it really is everyone, and I’m not personally driving any of them, but I am in a position to see what we’re having to do to deliver this stuff, the kinds of decisions PMs and designers need to make, and what makes it hard.
 Specifically, I’ll go into how we build viable applications that leverage LLMs, or what are called “foundation models.” I’ll be talking about “models” a lot today, and this will mean these kinds of things, large generative AI models that can work with text, images, video, etc. and that are available as a service, instead of requiring your organization to build them from scratch.
Specifically, I’ll go into how we build viable applications that leverage LLMs, or what are called “foundation models.” I’ll be talking about “models” a lot today, and this will mean these kinds of things, large generative AI models that can work with text, images, video, etc. and that are available as a service, instead of requiring your organization to build them from scratch.
 My ulterior motive here is that I tend to see PMs and designers converging on a single model: An everything chatbot, that hangs out with you and takes care of whatever you need it to do, as long as you type out a paragraph explaining what you want. I find that to be an insufficient plan for a couple of reasons.
My ulterior motive here is that I tend to see PMs and designers converging on a single model: An everything chatbot, that hangs out with you and takes care of whatever you need it to do, as long as you type out a paragraph explaining what you want. I find that to be an insufficient plan for a couple of reasons.
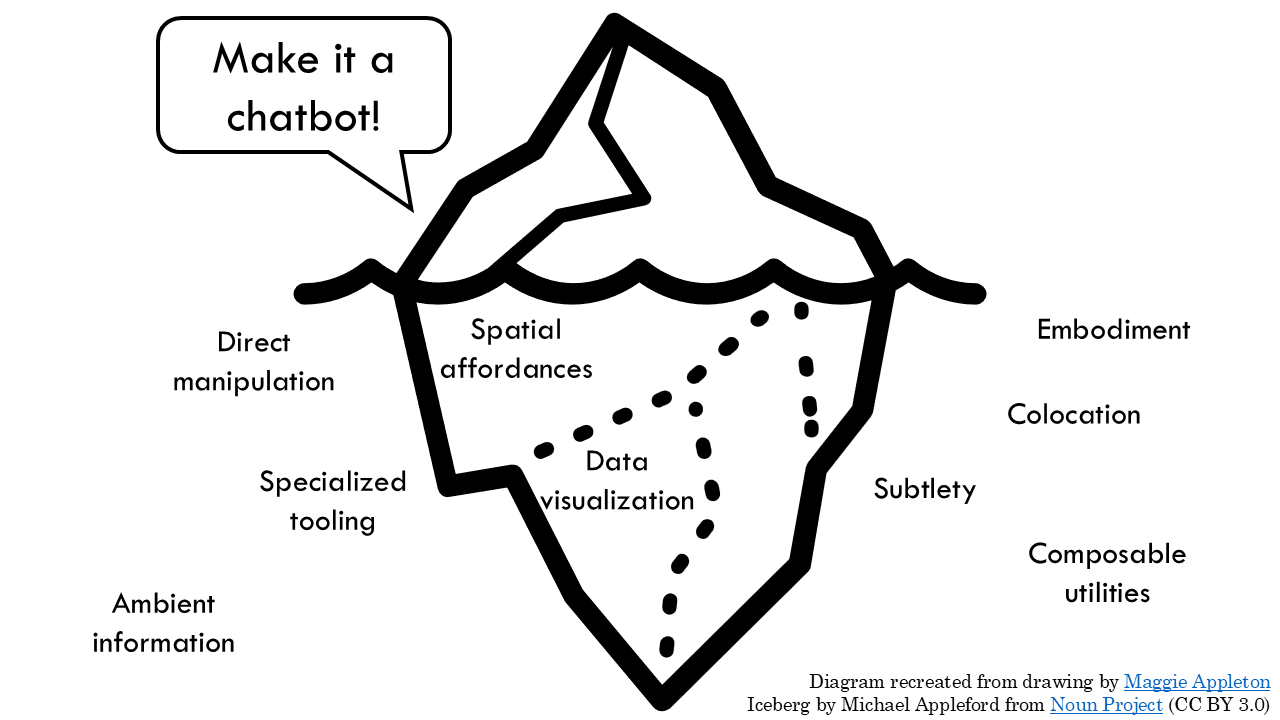 First, chat isn’t necessarily the best interface for lots of user tasks. It’s text-heavy, it’s turn-based, it requires a lot from the user, and it doesn’t necessarily set a lot of context for what the user is supposed to do. If you’ve gone to other Rosenfeld sessions recently, you might know a lot more about these kinds of UI patterns than I do, since the interface is not my job. BUT, A lot of these calls are made at the product strategy layer, when we’re even deciding what problem we’re trying to solve is, and what this thing is supposed to do. By defaulting to a chatbot, we’re introducing a lot of ambiguity that I suspect may be unnecessary.^[H/t to [[https://maggieappleton.com/lm-sketchbook|Maggie Appleton]] for this iceberg diagram.]
First, chat isn’t necessarily the best interface for lots of user tasks. It’s text-heavy, it’s turn-based, it requires a lot from the user, and it doesn’t necessarily set a lot of context for what the user is supposed to do. If you’ve gone to other Rosenfeld sessions recently, you might know a lot more about these kinds of UI patterns than I do, since the interface is not my job. BUT, A lot of these calls are made at the product strategy layer, when we’re even deciding what problem we’re trying to solve is, and what this thing is supposed to do. By defaulting to a chatbot, we’re introducing a lot of ambiguity that I suspect may be unnecessary.^[H/t to [[https://maggieappleton.com/lm-sketchbook|Maggie Appleton]] for this iceberg diagram.]
 Second, even if what you end up with is an everything chatbot, that’s almost certainly not how you’re going to build it, because it’s not particularly possible to optimize for everything.
Second, even if what you end up with is an everything chatbot, that’s almost certainly not how you’re going to build it, because it’s not particularly possible to optimize for everything.
Realistically, we’re building three apps in a trench coat, with an iffy interface slapped on top. At the very least, we need a way to think through what those apps are individually, and how we make them effective.
So, when we talk about building an AI application, what do we need to figure out?
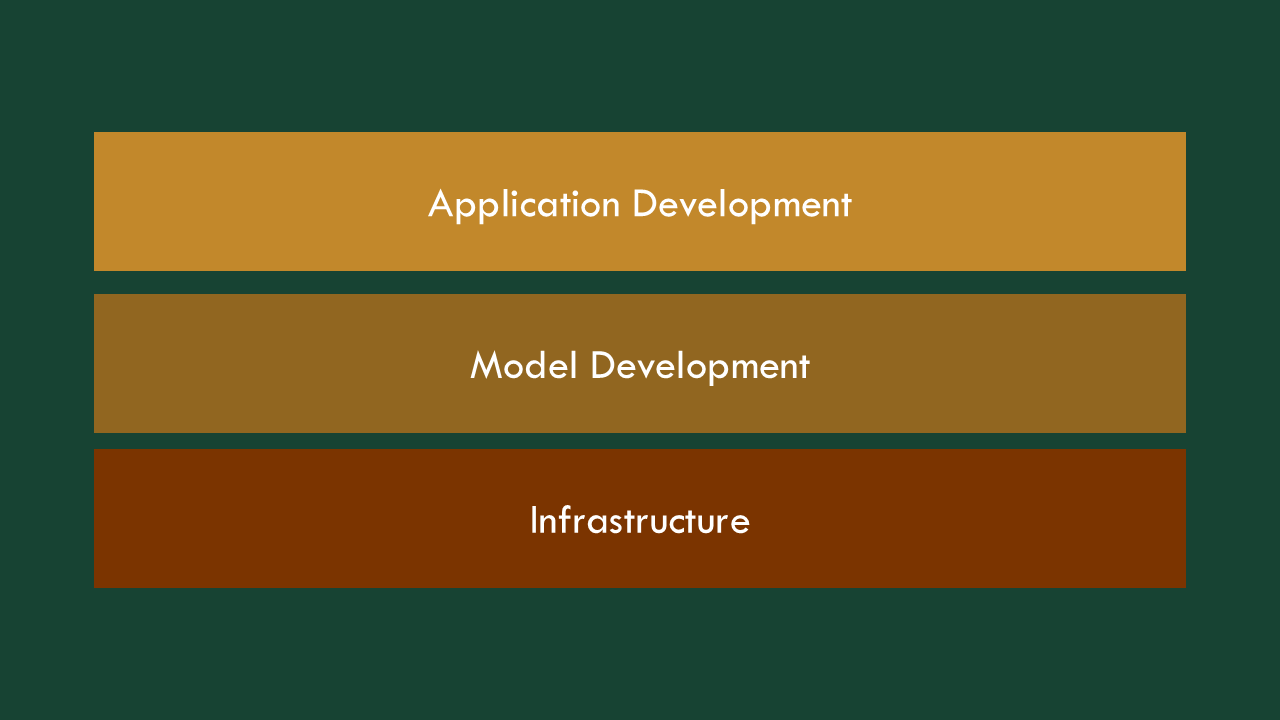 There are effectively three layers to building these things: building the app itself, figuring out the model, and then making sure there’s the infrastructure to make it all go. We’ll start from the bottom.
There are effectively three layers to building these things: building the app itself, figuring out the model, and then making sure there’s the infrastructure to make it all go. We’ll start from the bottom.
 This has stayed pretty much the same and is not really my problem so I’m going to ignore it.
This has stayed pretty much the same and is not really my problem so I’m going to ignore it.
 Next, there’s the model itself. A huge revolution has happened here, which is why we’re having this conversation, really. Most organizations that are building AI applications don’t have to manage their own models anymore. This is where speed and cost efficiency are managed, datasets are gotten from there to there, and models are trained or finetuned. Sometimes that’s necessary, but increasingly, the most important layer is the application layer.
Next, there’s the model itself. A huge revolution has happened here, which is why we’re having this conversation, really. Most organizations that are building AI applications don’t have to manage their own models anymore. This is where speed and cost efficiency are managed, datasets are gotten from there to there, and models are trained or finetuned. Sometimes that’s necessary, but increasingly, the most important layer is the application layer.
 The strategy for the application itself is incredibly important, not just for the user experience, but also the speeds we’re going to be able to achieve, how much this thing will cost, and whether we’ll even be able to tell whether we’re doing a good job. This all depends on the task the application is intended to help with, the context in which the feature occurs, what the interface itself is like, the prompt we send along with the user’s input, additional context we supply to that prompt, and how we evaluate how well the whole thing is working.
The strategy for the application itself is incredibly important, not just for the user experience, but also the speeds we’re going to be able to achieve, how much this thing will cost, and whether we’ll even be able to tell whether we’re doing a good job. This all depends on the task the application is intended to help with, the context in which the feature occurs, what the interface itself is like, the prompt we send along with the user’s input, additional context we supply to that prompt, and how we evaluate how well the whole thing is working.
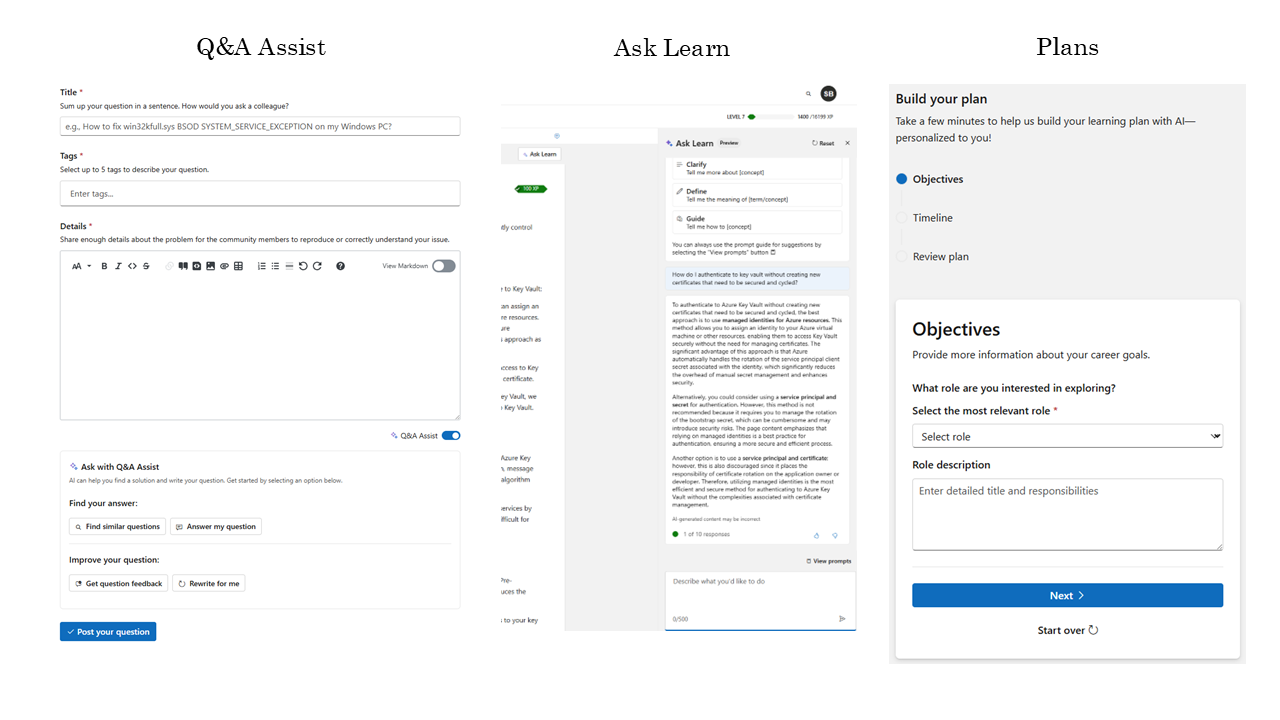 My team has done this a few times, to create several applications that all sit on Microsoft Learn and use AI to deliver different kinds of experiences.
My team has done this a few times, to create several applications that all sit on Microsoft Learn and use AI to deliver different kinds of experiences.
The first is Q&A Assist, it sits in a Stack Overflow-like question and answer experience. When a user goes to ask a new question, they have the option to use AI to find similar questions, get an answer, or get their question rewritten to have a better chance of a good answer.
Then there’s Ask Learn, an AI tutor that uses a chat interface and sits alongside training modules and can clarify the lesson, provide additional information, or give instructions.
Lastly, there’s a plan generation experience, where a user can tell us about a goal they have, like a job they want to get or a project they want to do, and we’ll use AI to recommend a set of training to do, along with reasonable time-based milestones, that they can further customize.
It’s worth noting that all of these sit on the same infrastructure and models, they just differ in the application development.
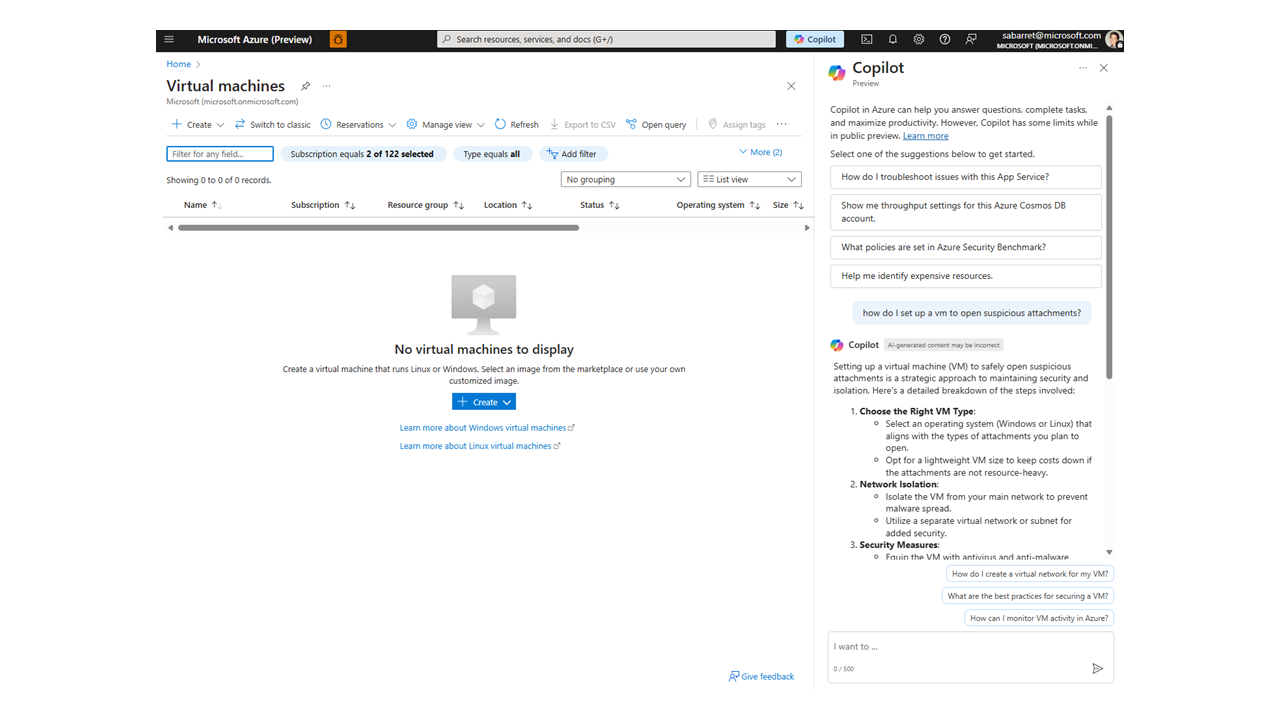 Our content is also one of the main sources for the Azure Portal Copilot, an experience my team does not build directly. This kind of distributed experience is becoming more common, so it will come into the story sometimes, too.
Our content is also one of the main sources for the Azure Portal Copilot, an experience my team does not build directly. This kind of distributed experience is becoming more common, so it will come into the story sometimes, too.
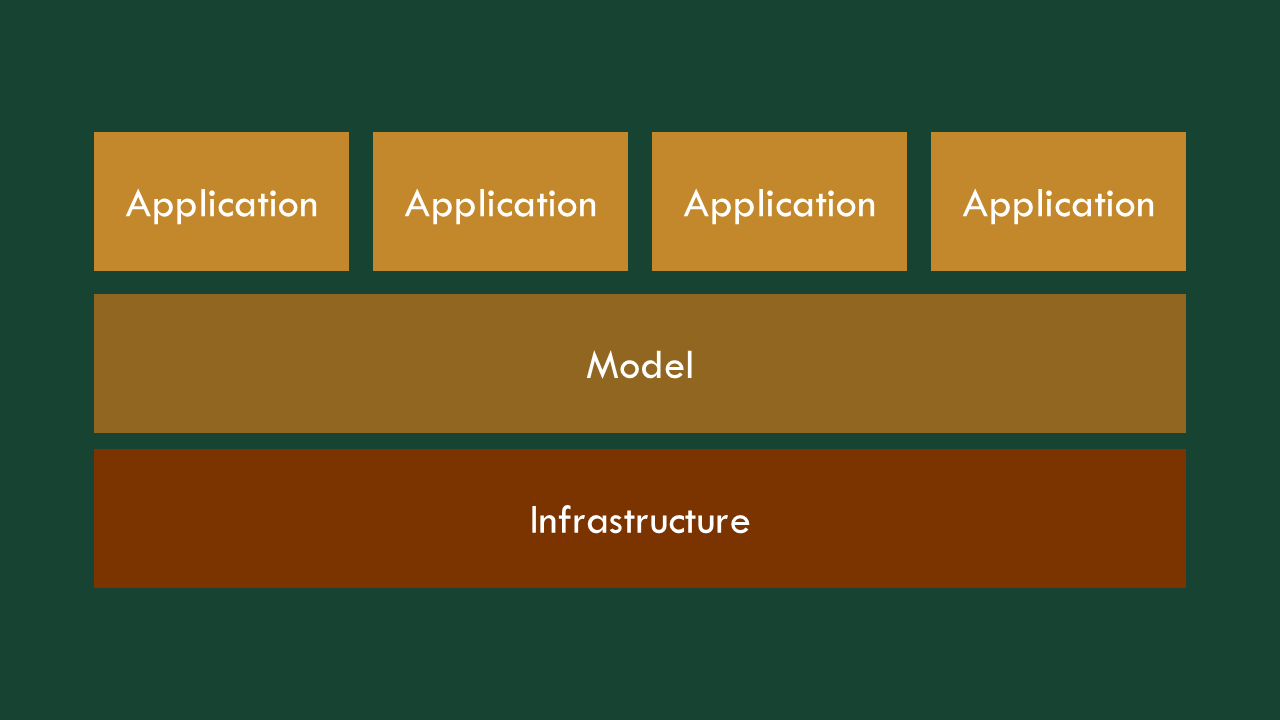 So we have an architecture where multiple, very different feeling applications, will all sit on top of the same model and infrastructure. That means tons of consequential decisions are being made in that application layer, that can make or break an experience.
So we have an architecture where multiple, very different feeling applications, will all sit on top of the same model and infrastructure. That means tons of consequential decisions are being made in that application layer, that can make or break an experience.
It can be kind of foreign to think through what makes these AI experiences easier or harder to build, because it’s just a little different than regular product management. There are several axes by which you can make your own job harder or easier as you’re designing these things.
 I’ve started thinking of it as an “ambiguity footprint.” Working with AI is ambiguous at best, because we’re in the realm of probabilistic, rather than deterministic, programming, but we don’t have to give up and say it’s ambiguity all the way down. We can see where that’s coming from, and actually map it, to see what we’re getting ourselves into.
I’ve started thinking of it as an “ambiguity footprint.” Working with AI is ambiguous at best, because we’re in the realm of probabilistic, rather than deterministic, programming, but we don’t have to give up and say it’s ambiguity all the way down. We can see where that’s coming from, and actually map it, to see what we’re getting ourselves into.
So, we’re going to go through the different aspects of the application layer and collect the axes we can use to understand the ambiguity in our AI apps.
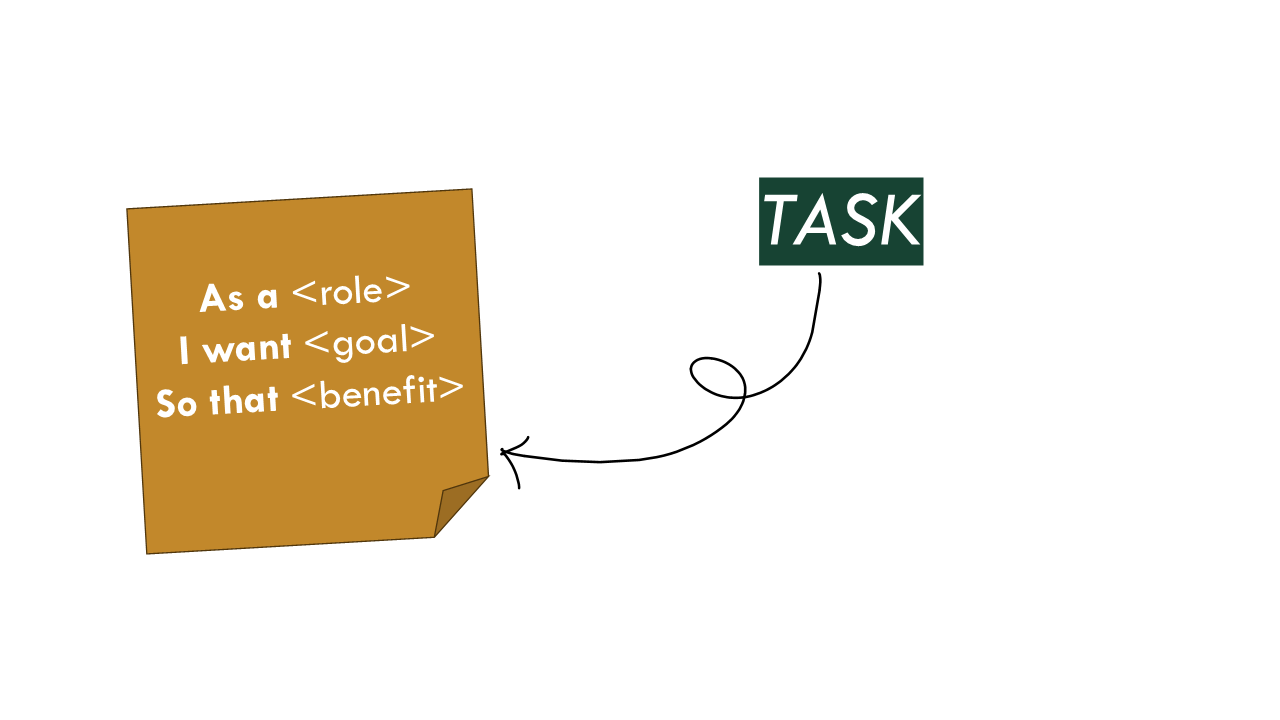 First, at the most basic level, is the task we are asking this AI app to do. The more complex it is, the less likely it is to be successful.
First, at the most basic level, is the task we are asking this AI app to do. The more complex it is, the less likely it is to be successful.
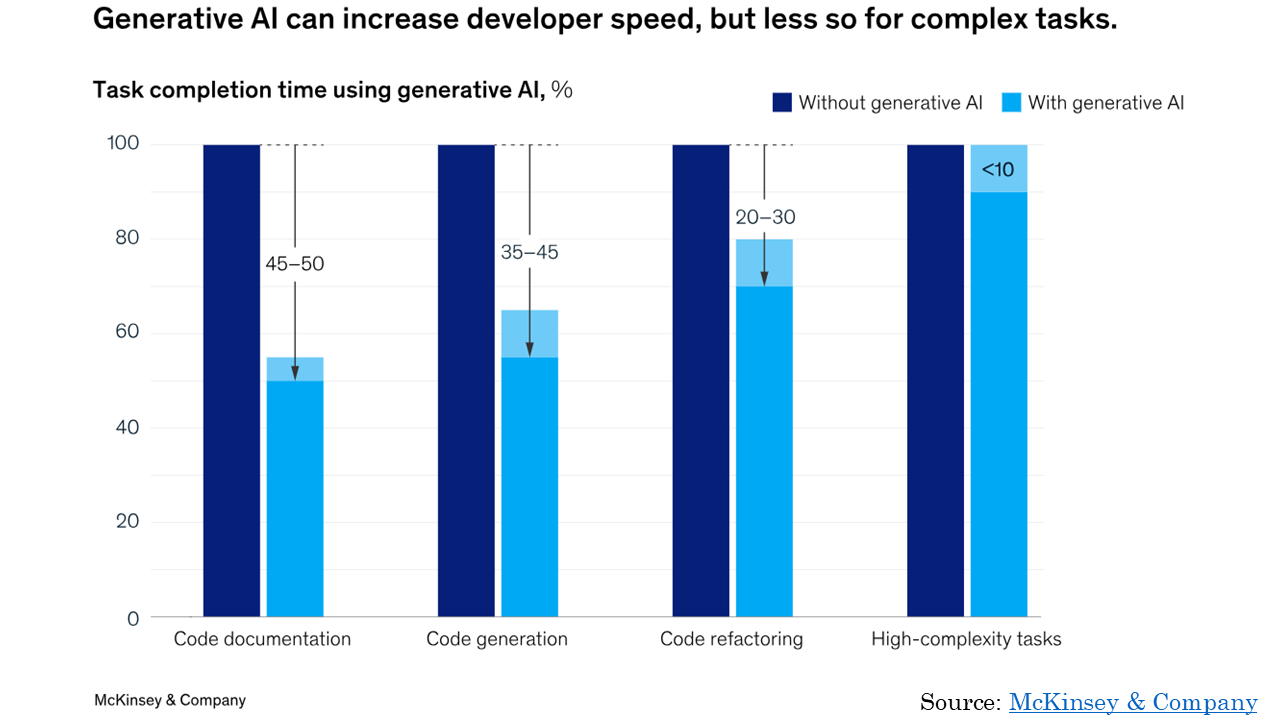 This is something we’re seeing in multiple domains. AI is currently most useful for tasks that are considered simpler. It helps more with documentation than it does with combining frameworks.
This is something we’re seeing in multiple domains. AI is currently most useful for tasks that are considered simpler. It helps more with documentation than it does with combining frameworks.
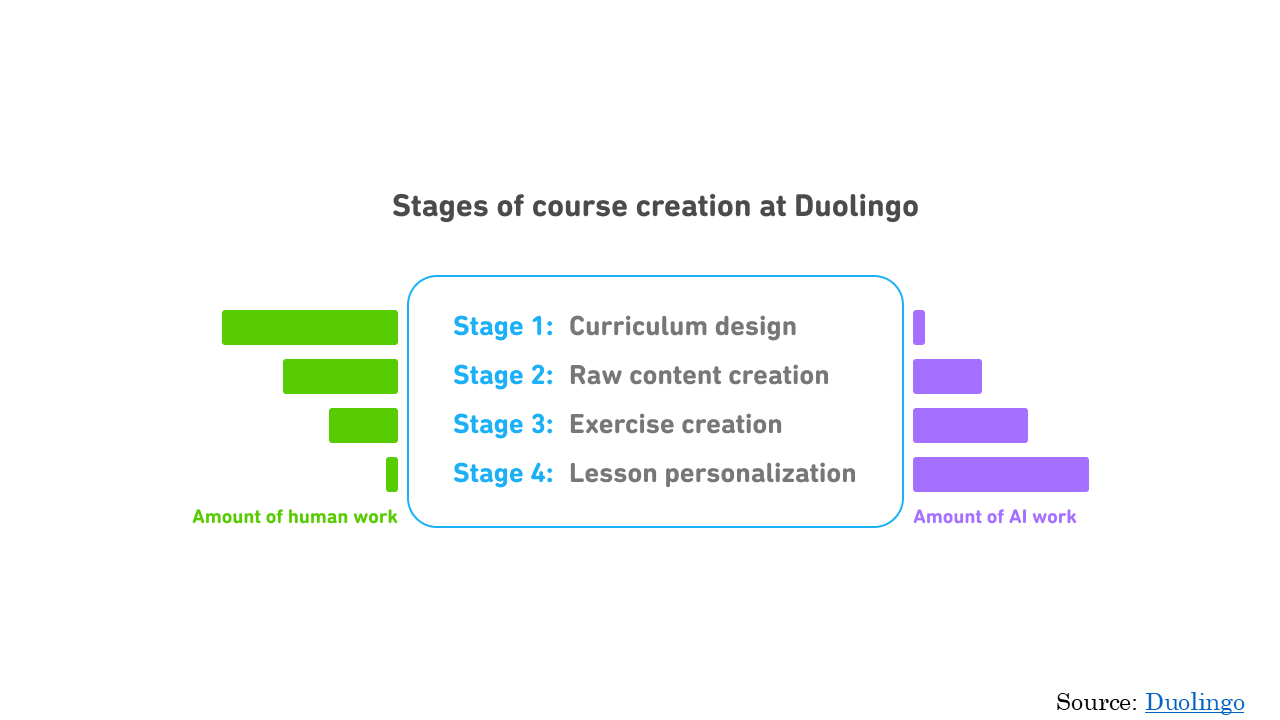 In a completely different domain, we similarly find that it helps more with lesson personalization than it does with curriculum design.
In a completely different domain, we similarly find that it helps more with lesson personalization than it does with curriculum design.
 So the more complex the task is, the trickier the application is going to be, because it’s something that any existing AI is less likely to help with. It’s also more likely to require multiple rounds of refinement or back and forth, called “multi-turn,” which rapidly becomes expensive.
So the more complex the task is, the trickier the application is going to be, because it’s something that any existing AI is less likely to help with. It’s also more likely to require multiple rounds of refinement or back and forth, called “multi-turn,” which rapidly becomes expensive.
You can already see how our “everything chatbot” is all the way on the complex side, because it can do anything.
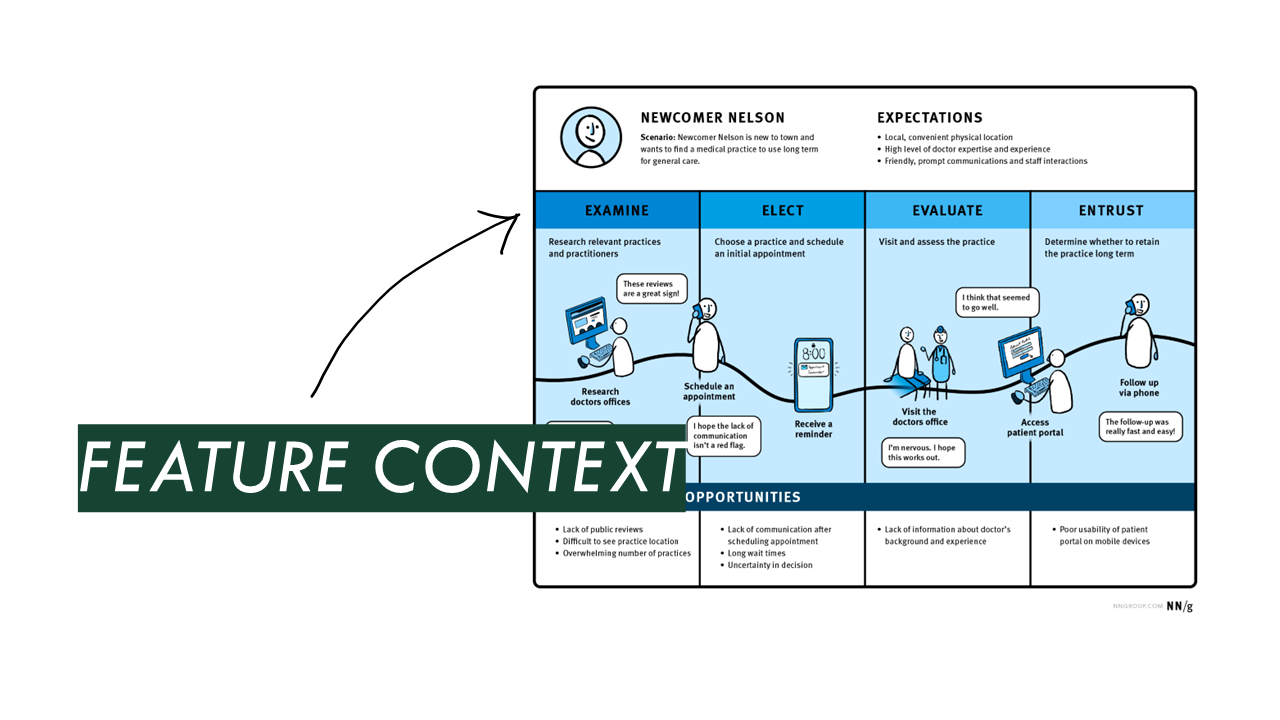 Next, we need to think through what the context of this app as a feature is. Aside from the task it’s doing, where does it sit in the user journey? What’s going on around it? What is the user doing before and after using it? Why are they using it?
Next, we need to think through what the context of this app as a feature is. Aside from the task it’s doing, where does it sit in the user journey? What’s going on around it? What is the user doing before and after using it? Why are they using it?
Depending on the answers to those questions, the stakes can get lower or higher.
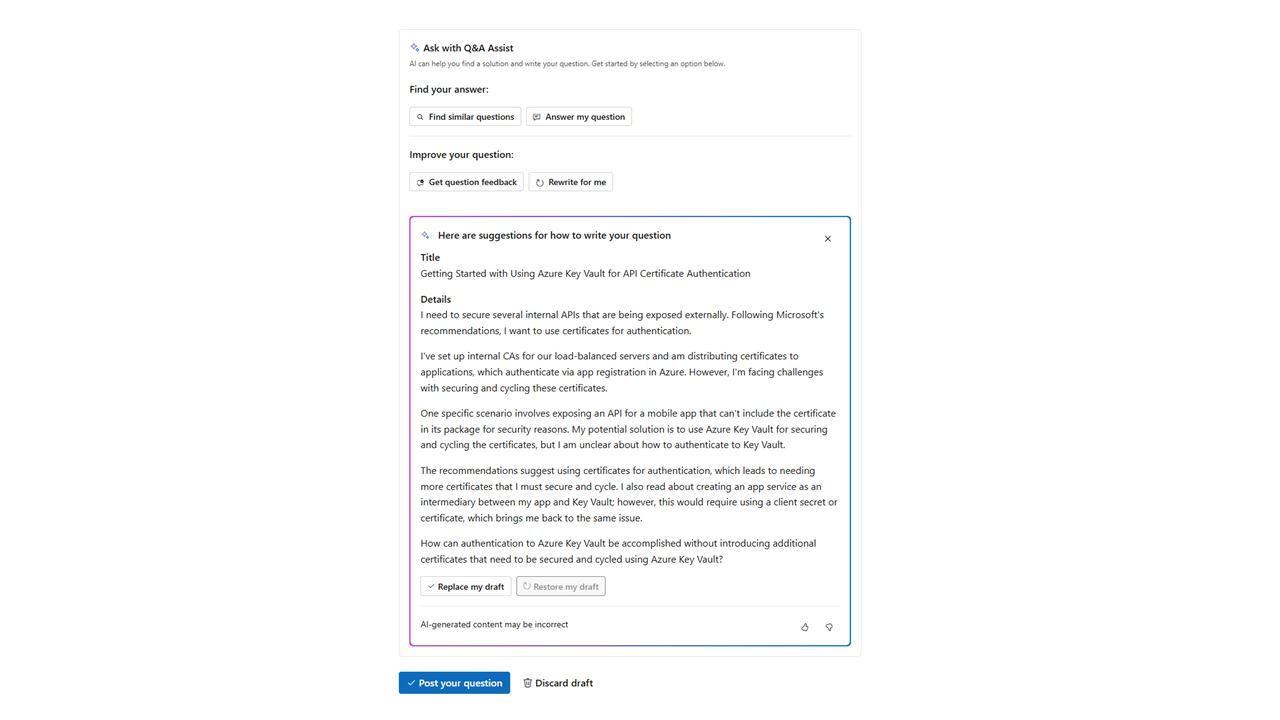 In this experience, on Q&A Assist, we use AI to help users rewrite their questions, to help their chances of getting a good answer from the community. We don’t delete their original question, we don’t post it for them, they don’t have to use our rewriting. It’s totally complementary to the main experience.
In this experience, on Q&A Assist, we use AI to help users rewrite their questions, to help their chances of getting a good answer from the community. We don’t delete their original question, we don’t post it for them, they don’t have to use our rewriting. It’s totally complementary to the main experience.
 A task where AI adds a little something is easier to get right than one where it’s a critical step. Similarly, a task that is nice to do is easier to get right than one that is a critical step in an essential user flow.
A task where AI adds a little something is easier to get right than one where it’s a critical step. Similarly, a task that is nice to do is easier to get right than one that is a critical step in an essential user flow.
Thinking of our everything chatbot, we don’t know what its feature context is because it’s everywhere, it does critical as well as complementary things, so it introduces a lot of ambiguity. It might even be the only way to get something done.
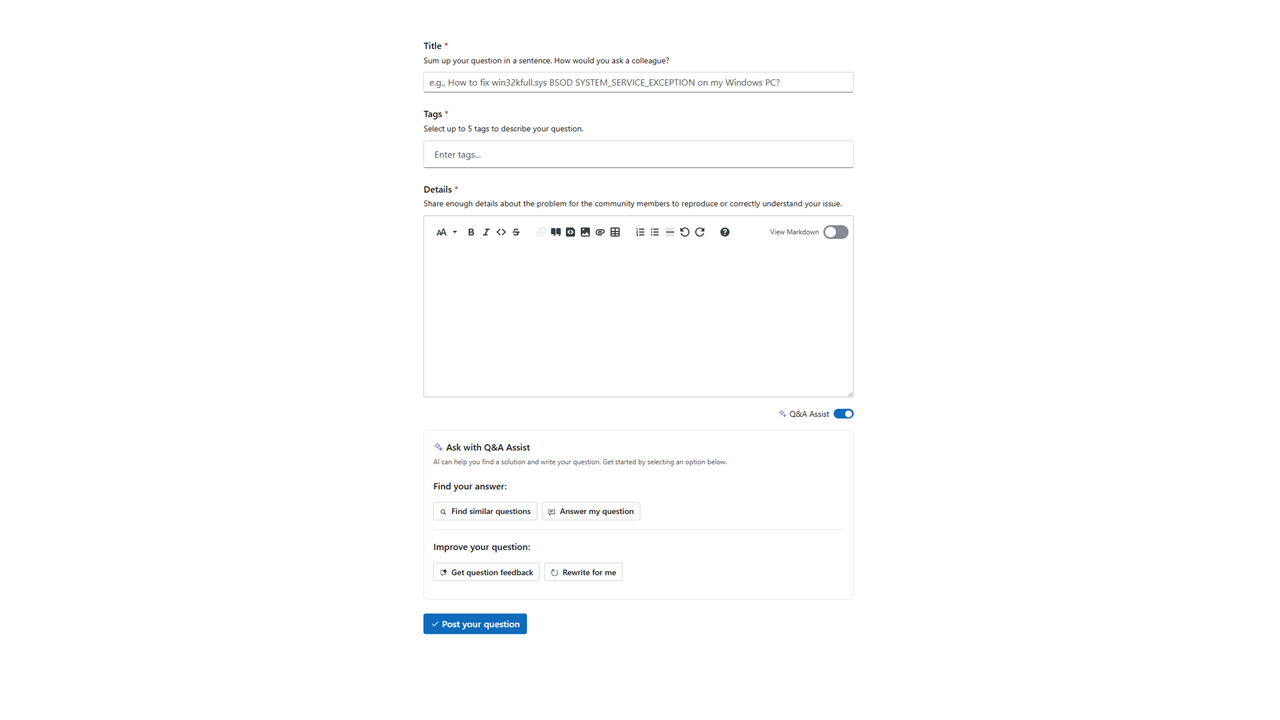 In Q&A Assist, before we even rewrite the question, a user has to invoke the feature, asking it for help. It doesn’t Clippy itself up in here, interrupting what people are doing.
In Q&A Assist, before we even rewrite the question, a user has to invoke the feature, asking it for help. It doesn’t Clippy itself up in here, interrupting what people are doing.
 If the app reacts to actions the user takes to deliberately invoke it, we’re introducing less risk than if it’s proactively inserting itself in their tasks.
If the app reacts to actions the user takes to deliberately invoke it, we’re introducing less risk than if it’s proactively inserting itself in their tasks.
Our everything chatbot is just an idea, but usually when people bring them up, they’re personable, suggesting things they can help with. They definitely verge on proactively inserting themselves into the experience.
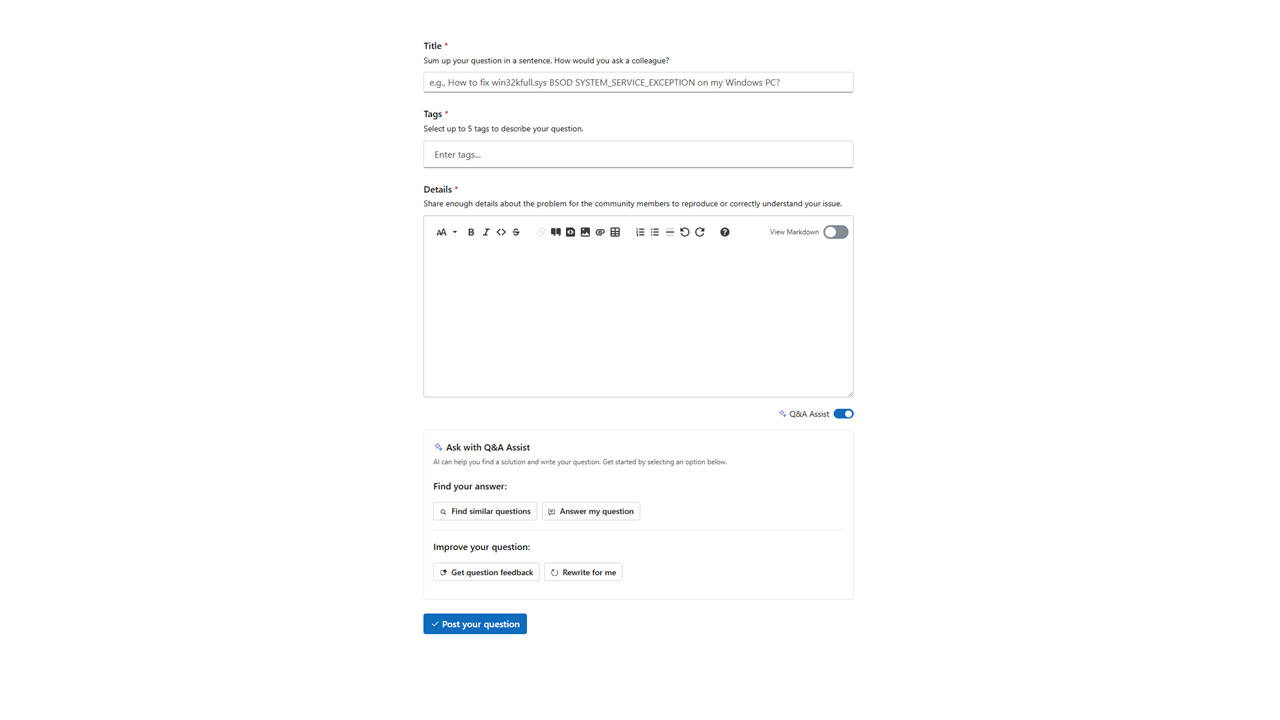 Lastly, we have to consider what information is the user working with at the time we’re introducing this app. In the context of Q&A Assist, it’s a question they were already planning to publish publicly on a question and answer site. That’s pretty mundane. If they were sharing something about a job search, the stakes get higher, if their social security number is in the mix, they get higher still.
Lastly, we have to consider what information is the user working with at the time we’re introducing this app. In the context of Q&A Assist, it’s a question they were already planning to publish publicly on a question and answer site. That’s pretty mundane. If they were sharing something about a job search, the stakes get higher, if their social security number is in the mix, they get higher still.
 So when we think about the context of the app, more mundane applications introduce less ambiguity. We don’t have to be as precise and users will be more tolerant.
So when we think about the context of the app, more mundane applications introduce less ambiguity. We don’t have to be as precise and users will be more tolerant.
Again, our everything chatbot handles everything, even the sensitive stuff.
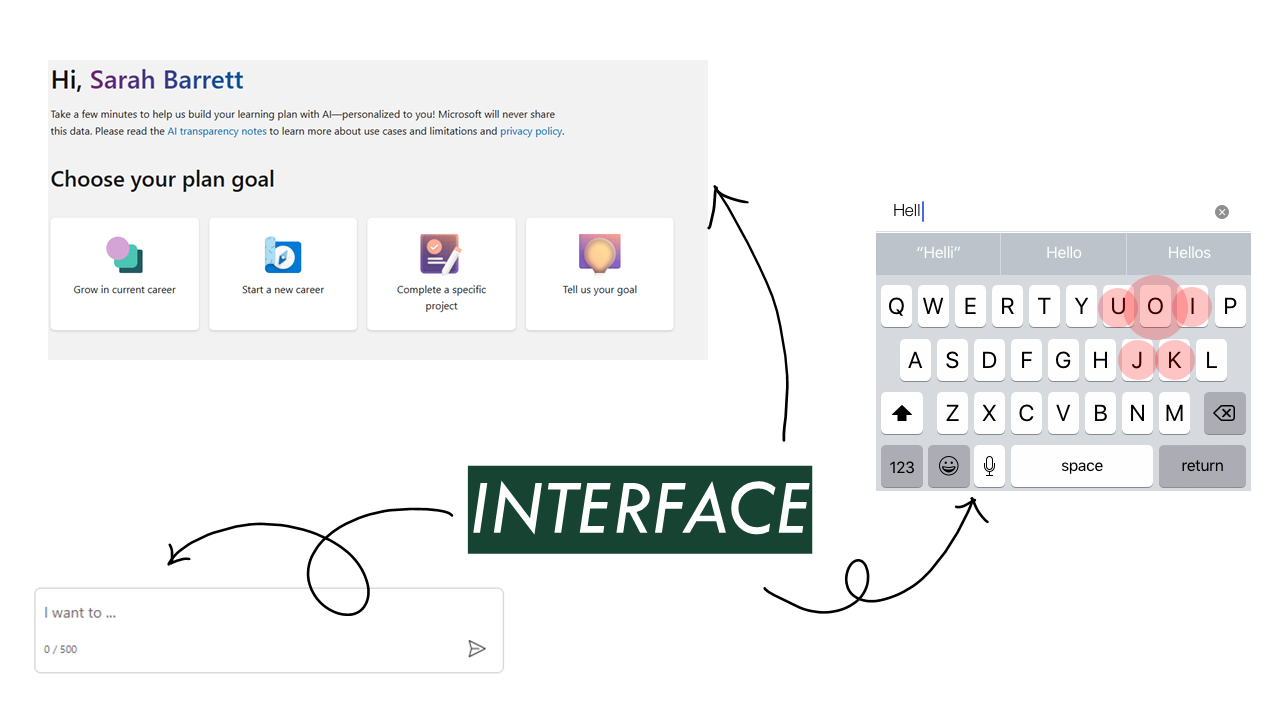 Next, the interface we give people does matter a lot, both in terms of how it works and the expectations it sets. All three of these represent interactions the user has with an AI application: Choosing from one of four options, tapping on a keyboard, and entering text in a box. They don’t all function, however, as equally visible AI interfaces. A user might not ever realize that their phone keyboard is using AI to optimize their tap targets for them. You can see that you’re clicking a button on a website, and we’re telling you it uses AI. And in a chatbot, it’s very apparent that you’re entering information.
Next, the interface we give people does matter a lot, both in terms of how it works and the expectations it sets. All three of these represent interactions the user has with an AI application: Choosing from one of four options, tapping on a keyboard, and entering text in a box. They don’t all function, however, as equally visible AI interfaces. A user might not ever realize that their phone keyboard is using AI to optimize their tap targets for them. You can see that you’re clicking a button on a website, and we’re telling you it uses AI. And in a chatbot, it’s very apparent that you’re entering information.
 Those exist on a spectrum of invisible interfaces to very visible ones. Visible interfaces aren’t worse! It just introduces another thing you’re communicating to users and another place where you introduce ambiguity.
Those exist on a spectrum of invisible interfaces to very visible ones. Visible interfaces aren’t worse! It just introduces another thing you’re communicating to users and another place where you introduce ambiguity.
An everything chatbot is visible, you use it directly.
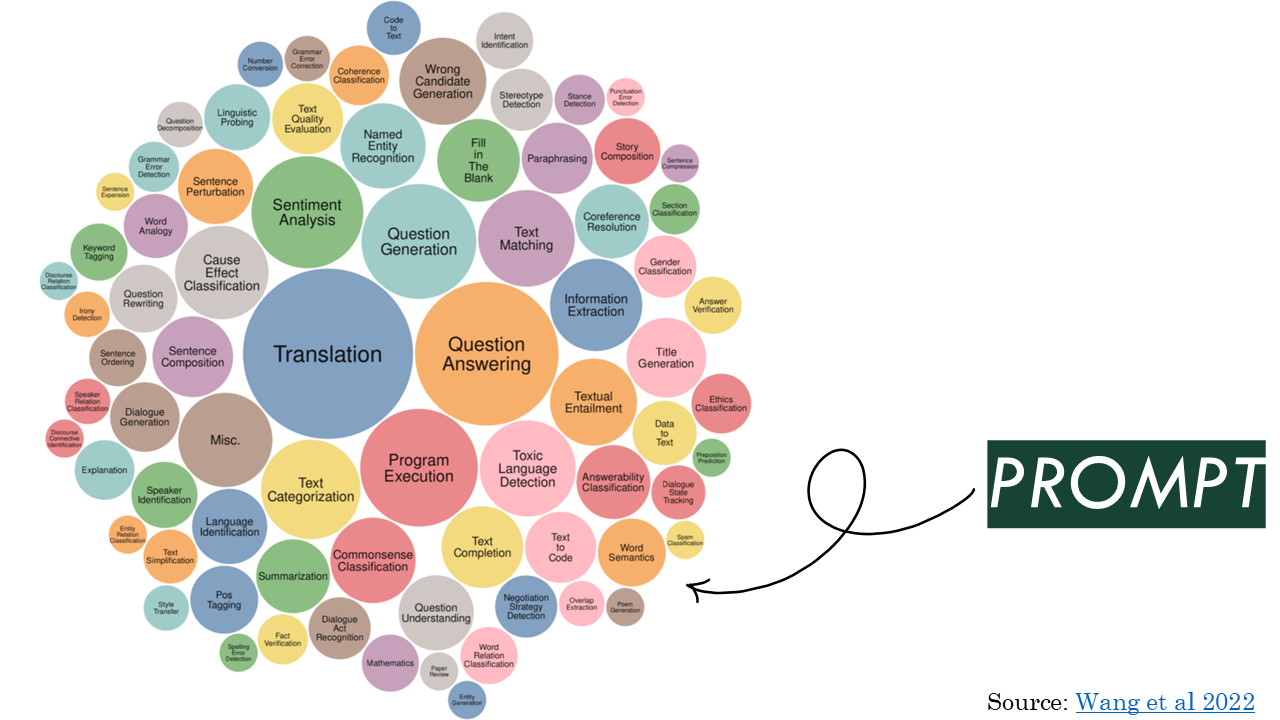 The same model can do lots of different things. These are the tasks that are sometimes used to benchmark foundation models, showing many kinds of things that they may be able to do.
The same model can do lots of different things. These are the tasks that are sometimes used to benchmark foundation models, showing many kinds of things that they may be able to do.
What can be confusing, though, is that very similar interfaces can conceal very different prompts. I find it most useful to think about these prompts on a spectrum of “closed,” meaning that they limit the acceptable inputs and outputs to a specific kind of interaction, to “open,” where many kinds of inputs and outputs are possible. Of course, no LLM output is truly closed, but prompt engineering can limit the scope from the whole world, to a few types of things.
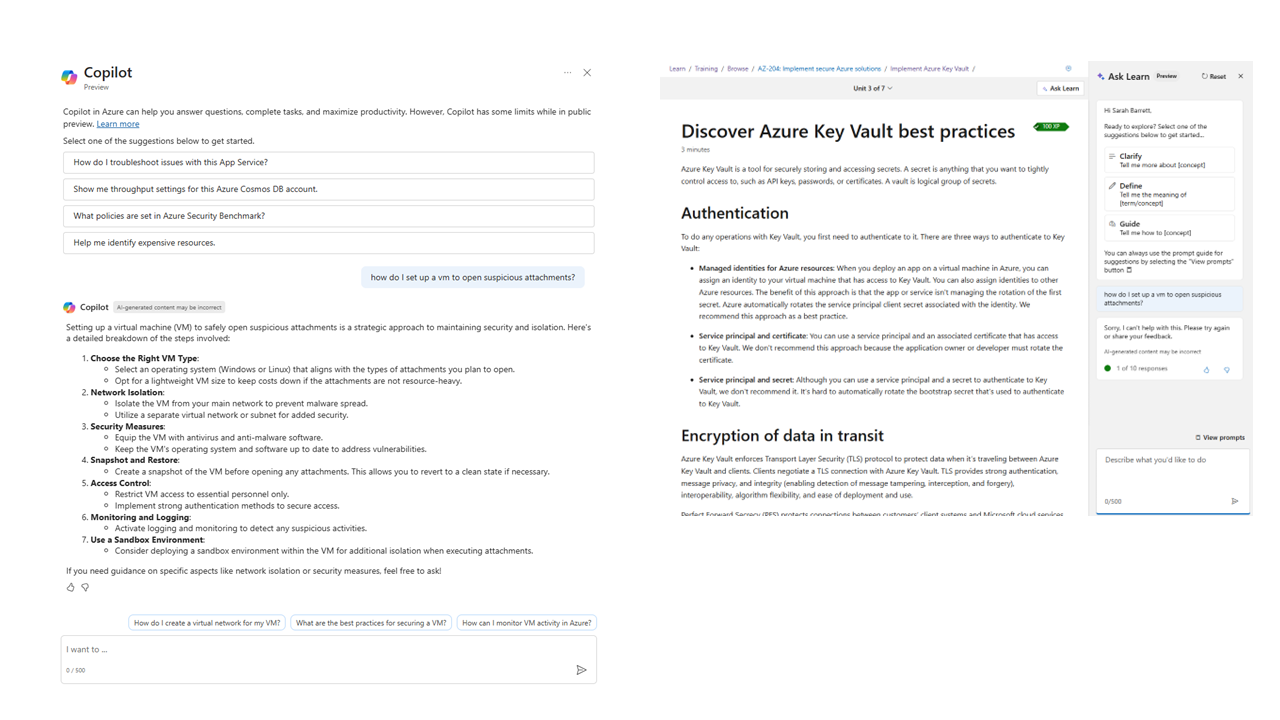 These two very similar looking interfaces (a chat box as a sidecar on a website) end up doing pretty different things because of how their prompting works. A user inputs a question or a message, but each of these adds to it substantially. They wrap the query you send them in a long string of text, telling the model what its name is, what its role is, the possible tasks it can do, the things it absolutely should not do, and the language it should use. On the right, we give the model a prompt of about 3000 words, not counting the user’s query and necessary context, and I don’t think that’s a particularly egregious prompt.
These two very similar looking interfaces (a chat box as a sidecar on a website) end up doing pretty different things because of how their prompting works. A user inputs a question or a message, but each of these adds to it substantially. They wrap the query you send them in a long string of text, telling the model what its name is, what its role is, the possible tasks it can do, the things it absolutely should not do, and the language it should use. On the right, we give the model a prompt of about 3000 words, not counting the user’s query and necessary context, and I don’t think that’s a particularly egregious prompt.
The Copilot in the Azure Portal, on the left, is equipped by its prompt to do lots of things. It will answer questions, make changes to resources, tell you about the status of your apps, etc. It will tell me how to open suspicious attachments in virtual machine, because the prompt it wraps my question in is a lot more open.
The Ask Learn sidecar on the right, by contrast, only answers learning questions that are sufficiently related to the specific learning content you’re looking at. This assistant on an Azure Key Vault Best Practices lesson won’t answer questions about how to open suspicious attachments in a virtual machine, even though that’s not a nefarious user prompt.
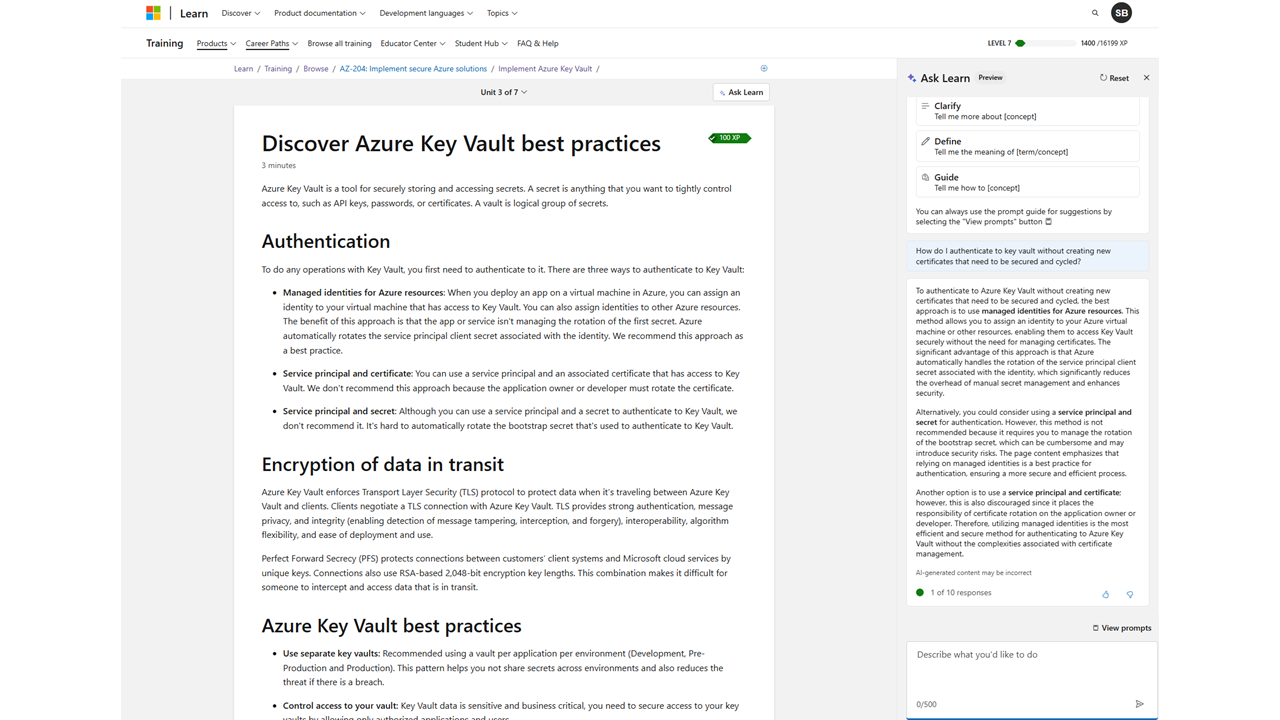 When you ask something that the agent identifies as more part of its mandate, it returns a response.
When you ask something that the agent identifies as more part of its mandate, it returns a response.
This is not perfect! By massaging the terms you use, sometimes it will answer slightly off topic things, sometimes it won’t, which is not ideal.
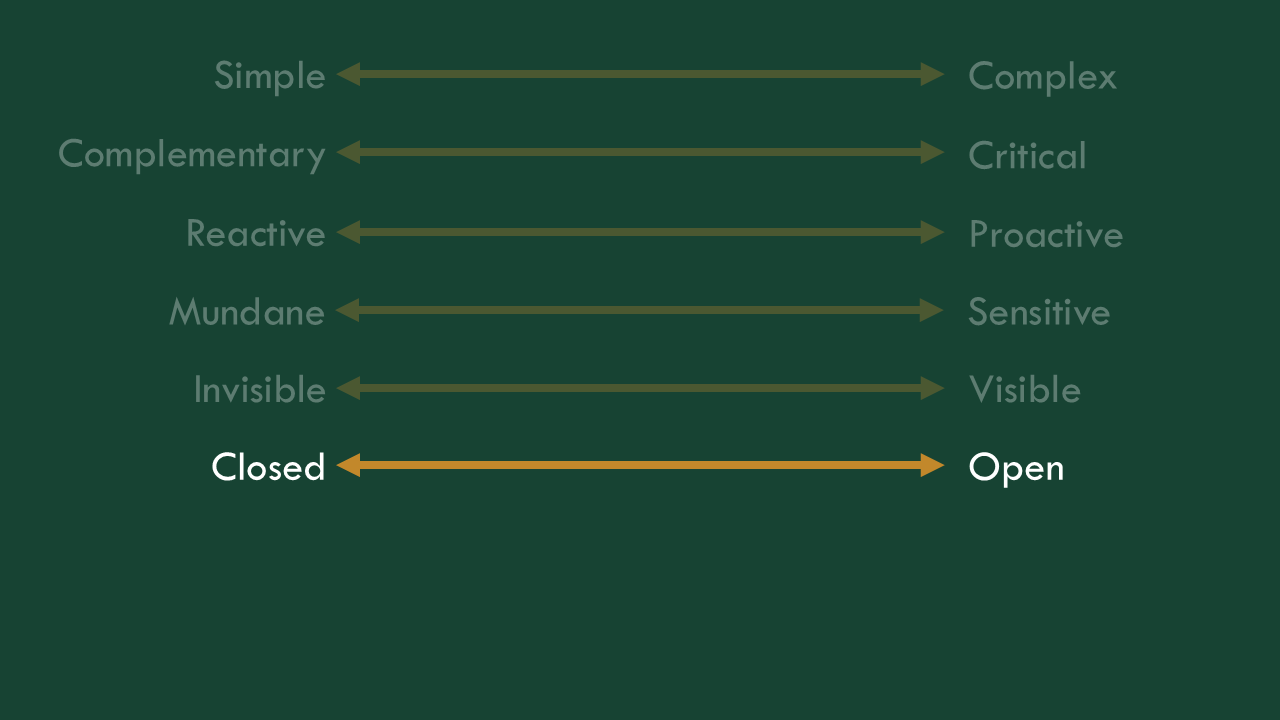 So even though the interface is almost exactly the same, one of these will only do a couple of things it’s limited to by its prompt, the other is, by design, much more open. With that openness comes power, but also, by definition, ambiguity.
So even though the interface is almost exactly the same, one of these will only do a couple of things it’s limited to by its prompt, the other is, by design, much more open. With that openness comes power, but also, by definition, ambiguity.
Our everything chatbot is the definition of open, it does everything!
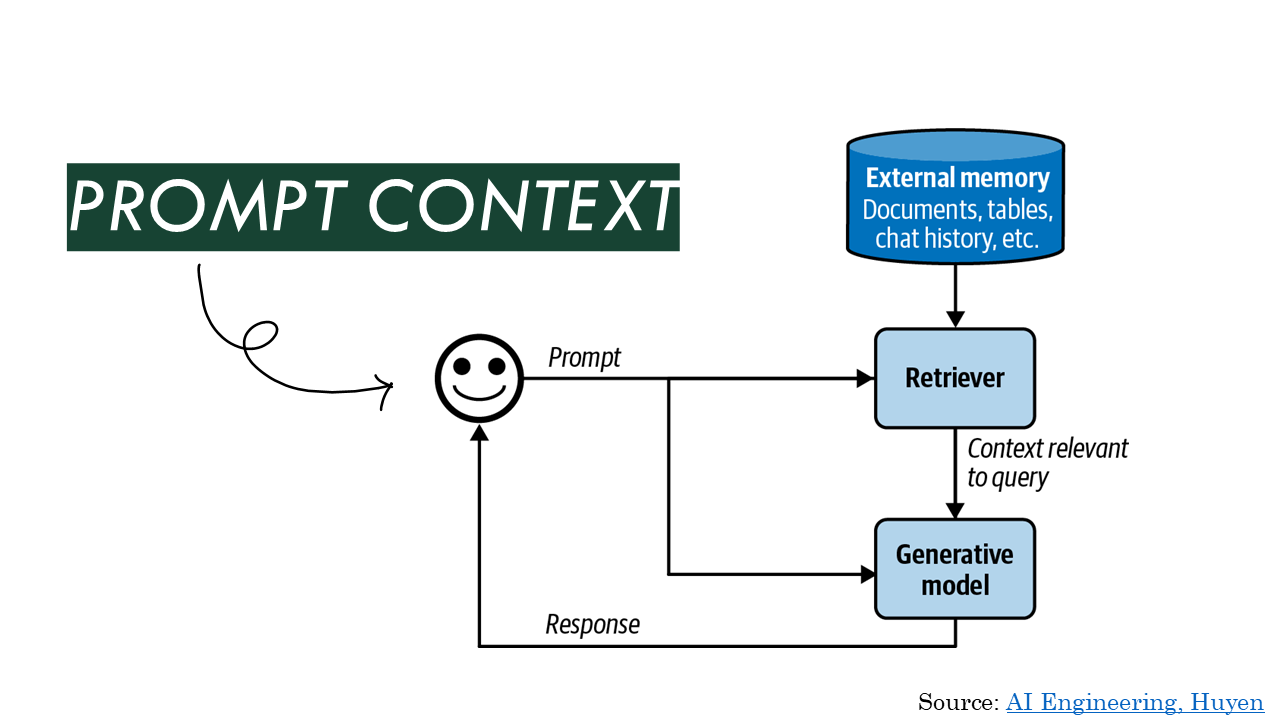 In addition to the prompt, what you send to the model also usually contains context. Context is the additional information you pass along with the user’s message and the prompt you added to it. In some cases, this might be the text of every page you have in a knowledge base, just pasted in as text. (I’ve seen information suggesting that if you have around 500 pages of text or fewer, this works fine.) In other cases, it’s search results, the text of the page the user is looking at when they make the query, or the chat history. Supplying information from search results is usually called RAG, or retrieval-augmented-generation.
In addition to the prompt, what you send to the model also usually contains context. Context is the additional information you pass along with the user’s message and the prompt you added to it. In some cases, this might be the text of every page you have in a knowledge base, just pasted in as text. (I’ve seen information suggesting that if you have around 500 pages of text or fewer, this works fine.) In other cases, it’s search results, the text of the page the user is looking at when they make the query, or the chat history. Supplying information from search results is usually called RAG, or retrieval-augmented-generation.
A situation where you always give the model the whole corpus, because it’s small enough, is straightforward. You just have to update what you send when the corpus changes. If you have more content that you want to retrieve and segment before you use it generation, you can often get better results, but there’s now more to build. You have to have a queryable store of your content, you have to have a retriever that gets the right parts of your content, you need it broken down into workable data chunks, etc. etc.
 So if the context you’re giving the model along with each prompt is static, it’s more straightforward than if you’re managing dynamic context that goes along with each interaction.
So if the context you’re giving the model along with each prompt is static, it’s more straightforward than if you’re managing dynamic context that goes along with each interaction.
To do an everything chatbot well, I think it needs a lot of dynamic context. It would need to know where a user is in an experience, what they’ve been doing, and what the contents of their documents or whatever they’re working on is. It might also need a lot of background information on how these kinds of things are supposed to work, so it can help a user. That’s a lot of dynamic context that, again, introduces more ambiguity and more stuff to build.
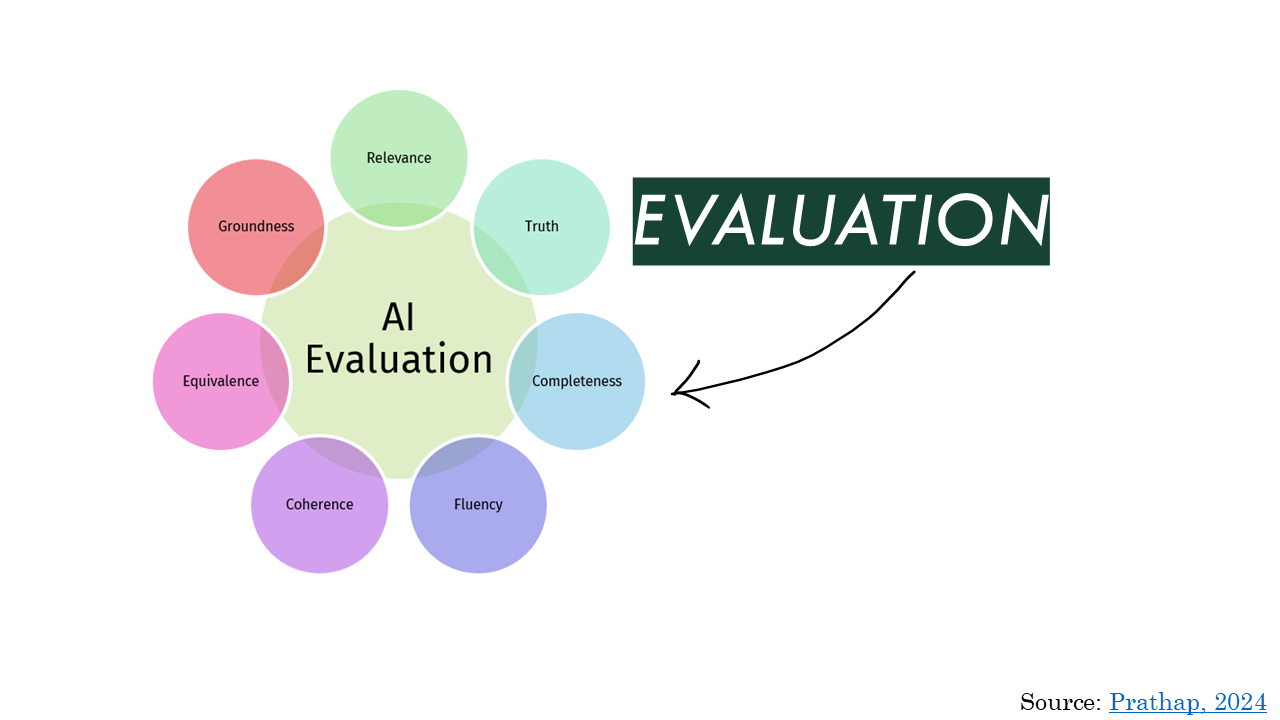 Lastly, and most importantly, you need to figure out whether the model and the app are doing what they’re supposed to be doing, consistently. This is one model for thinking about quality in AI, I’m not endorsing it, but it does show that there are lots of ways to think about it.
Lastly, and most importantly, you need to figure out whether the model and the app are doing what they’re supposed to be doing, consistently. This is one model for thinking about quality in AI, I’m not endorsing it, but it does show that there are lots of ways to think about it.
The thing is, because it’s this tricky area and there’s lots that goes into correctness, I see wanting to people skip or handwave this step a troubling amount of the time.
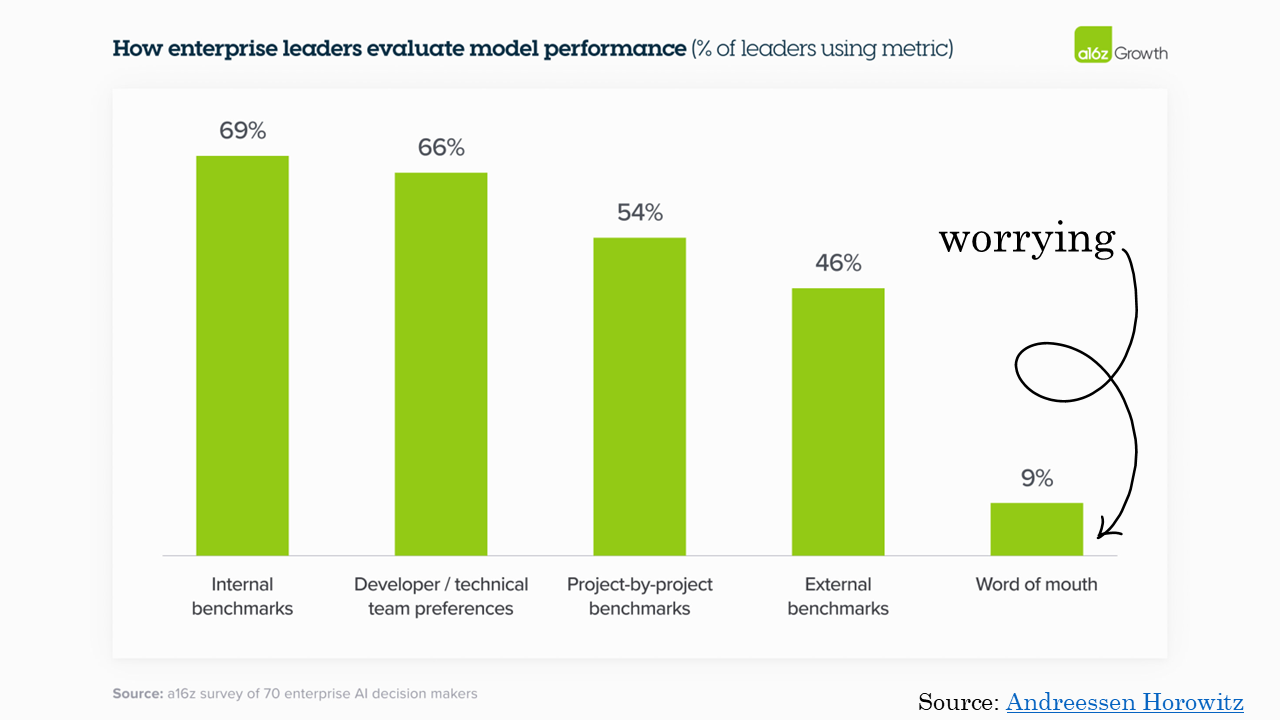 According to this survey, which, who knows, but, fully 9% of the decision-makers they survey admitted to just asking around and calling it good. I know 9% isn’t a huge number, but for what we are asking these tools to do, it’s entirely too much! Anecdotally, I think a lot of these “internal benchmarks” and “developer preferences” are someone working on it looking at the output and going “Eh, looks fine.”
According to this survey, which, who knows, but, fully 9% of the decision-makers they survey admitted to just asking around and calling it good. I know 9% isn’t a huge number, but for what we are asking these tools to do, it’s entirely too much! Anecdotally, I think a lot of these “internal benchmarks” and “developer preferences” are someone working on it looking at the output and going “Eh, looks fine.”
This is a problem! How you figure out what good is, what success would look like, is a perennial problem in product management and UX. It matters here, too, because otherwise there’s no real way to tell which model to use or tell when you’re done optimizing it. You’re just operating on vibes.
If you take one thing away from this talk, it’s this: Plan on this being a major part of your development effort. (It might even be the majority.) Otherwise, you risk just eyeballing the results, which doesn’t work. These things are expensive, and if you don’t have a way of evaluating your results, you have no way to tell if it’s earning its keep.
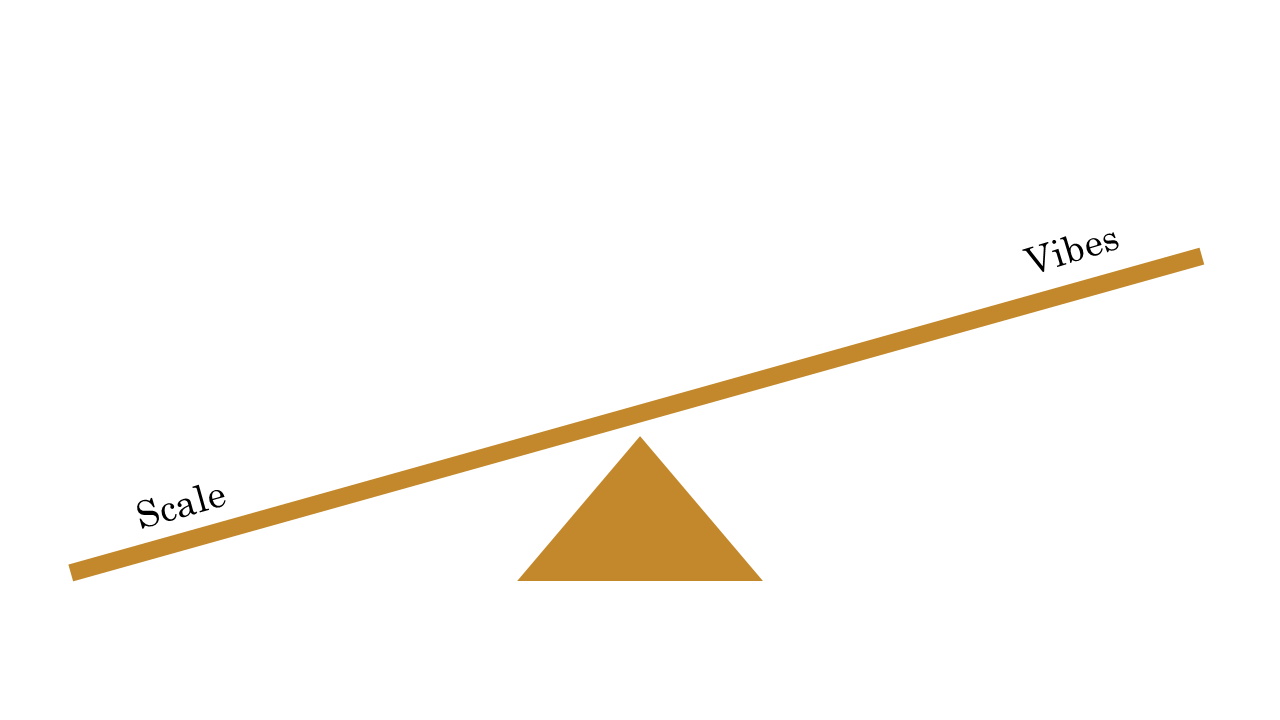 While evaluation is important, I think the main reason it’s skipped is that it’s not easy. The scale is intimidating, and many people don’t know how to set up a program to spot check and generalize insights to improve huge datasets.
While evaluation is important, I think the main reason it’s skipped is that it’s not easy. The scale is intimidating, and many people don’t know how to set up a program to spot check and generalize insights to improve huge datasets.
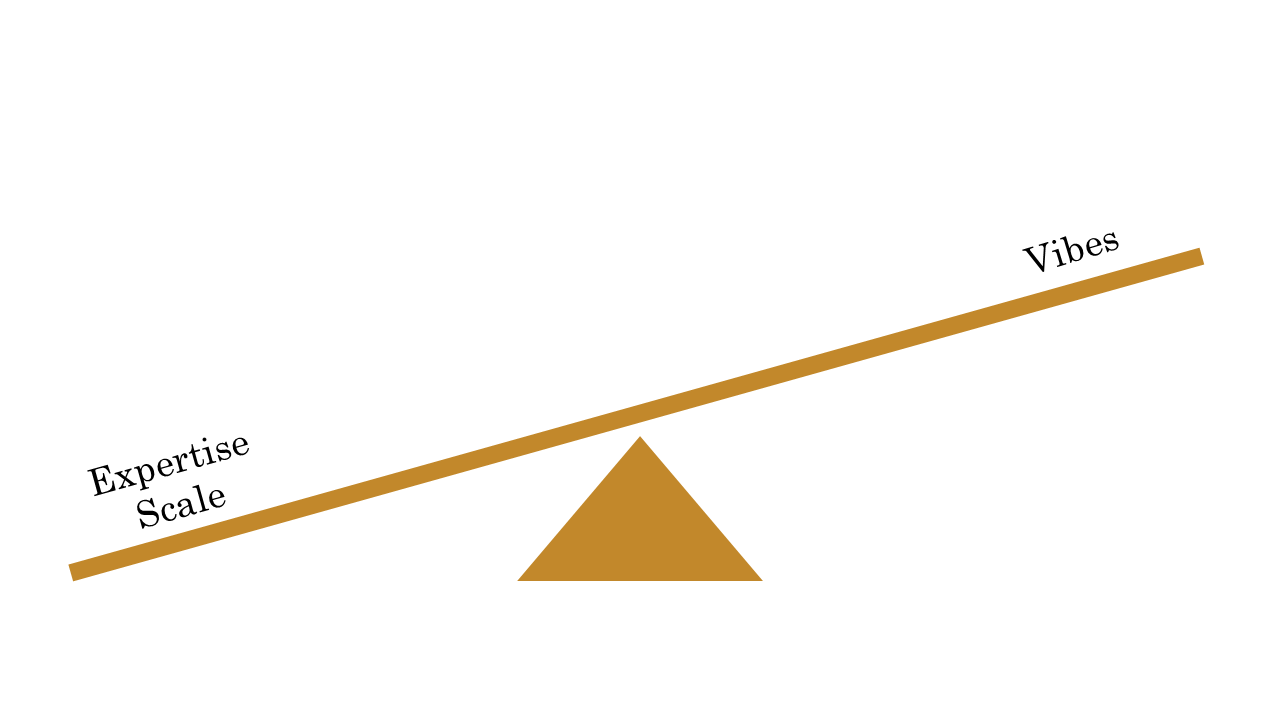 It can also be hard to evaluate the outputs if the evaluators lack the expertise to tell whether the answers are right. I come from a taxonomy background, and it’s hard enough to tell consistently what something is about, much less whether it accurately explains how to handle certificate rotation, or whatever else people are asking about. That’s something to consider early on, when you’re determining what tasks you want an AI application to help with.
It can also be hard to evaluate the outputs if the evaluators lack the expertise to tell whether the answers are right. I come from a taxonomy background, and it’s hard enough to tell consistently what something is about, much less whether it accurately explains how to handle certificate rotation, or whatever else people are asking about. That’s something to consider early on, when you’re determining what tasks you want an AI application to help with.
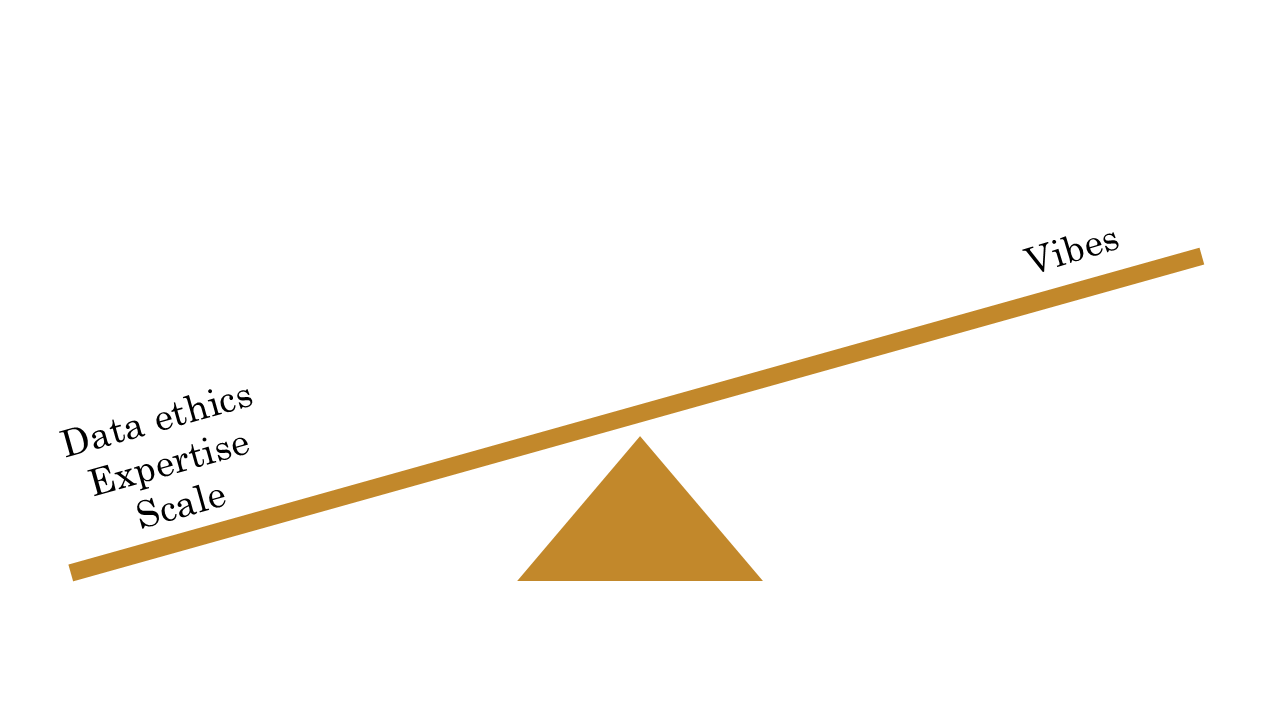 Lastly, depending on where your application is vs where your data is and the standards you’re held to, data ethics can make it impossible to get information about what’s happening in your app or enough context to tell whether it’s good. We know our content flows out to ChatGPT via web scraping, but we have no idea how well it works in the context of their application, because we don’t and shouldn’t have their data. Even closer to home, we know very little about how our content gets used in the Azure portal copilot, because we don’t and shouldn’t have that data either.
Lastly, depending on where your application is vs where your data is and the standards you’re held to, data ethics can make it impossible to get information about what’s happening in your app or enough context to tell whether it’s good. We know our content flows out to ChatGPT via web scraping, but we have no idea how well it works in the context of their application, because we don’t and shouldn’t have their data. Even closer to home, we know very little about how our content gets used in the Azure portal copilot, because we don’t and shouldn’t have that data either.
 So, there are lots of things that contribute to evaluation being hard, but the one that I see surprising people working on AI apps is how distributed the experience of the app is. Depending on where it’s being used, you may not even be able to get data to tell whether it’s working.
So, there are lots of things that contribute to evaluation being hard, but the one that I see surprising people working on AI apps is how distributed the experience of the app is. Depending on where it’s being used, you may not even be able to get data to tell whether it’s working.
For most organizations large enough to be considering a real everything chatbot, you probably can’t ethically share details from one part of that org to another. If there’s any chance of it being used internationally, that opens up a whole other can of worms. Even if you’d like to just look at what it’s doing and see if it’s good, you may not be able to. That introduces a huge blind spot and a lot of ambiguity.
 So we’ve talked through all these axes, representing the product decisions that introduce more ambiguity, and therefore make these things harder and more expensive to build and run effectively. I’ve gone through our experiences and charted them, based on my own opinions, from 1 to 3 on each axis. 1 being little ambiguity of that kind, 3 being a lot. So we can see how this stuff falls out.
So we’ve talked through all these axes, representing the product decisions that introduce more ambiguity, and therefore make these things harder and more expensive to build and run effectively. I’ve gone through our experiences and charted them, based on my own opinions, from 1 to 3 on each axis. 1 being little ambiguity of that kind, 3 being a lot. So we can see how this stuff falls out.
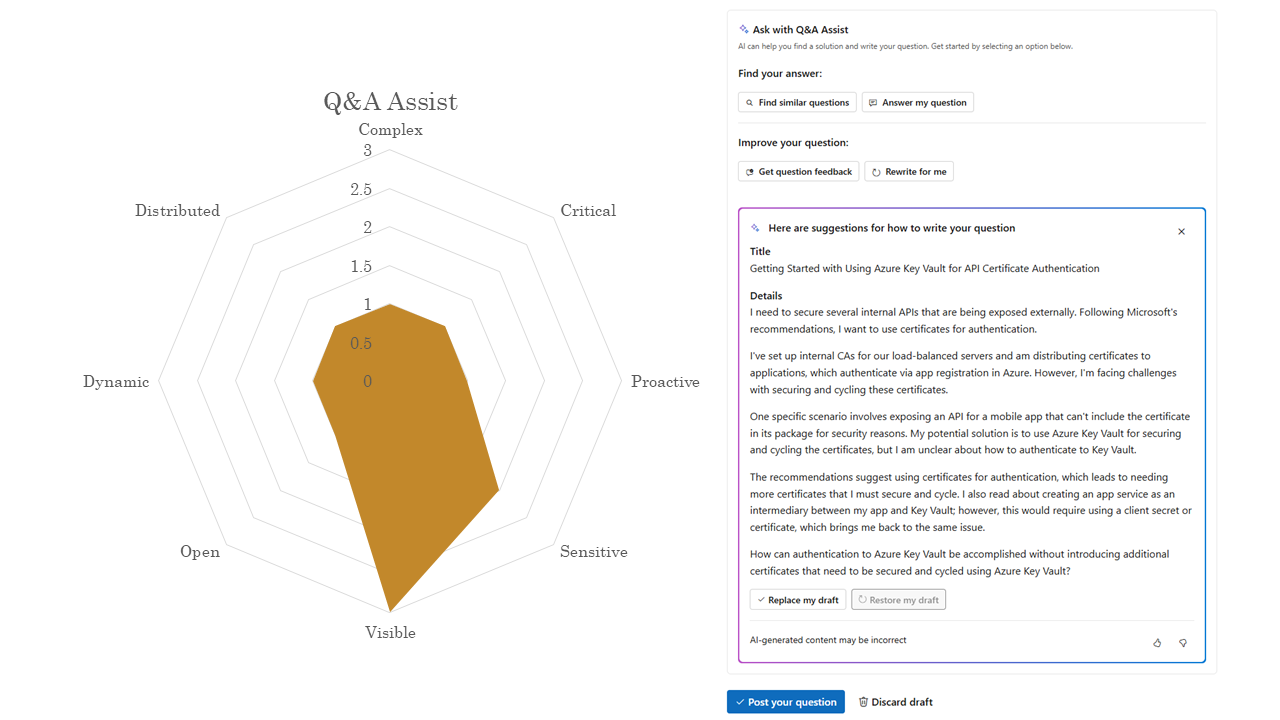 Q&A Assist is visible to users, and they might put something sensitive in, we have no idea, but otherwise, its footprint is quite small.
Q&A Assist is visible to users, and they might put something sensitive in, we have no idea, but otherwise, its footprint is quite small.
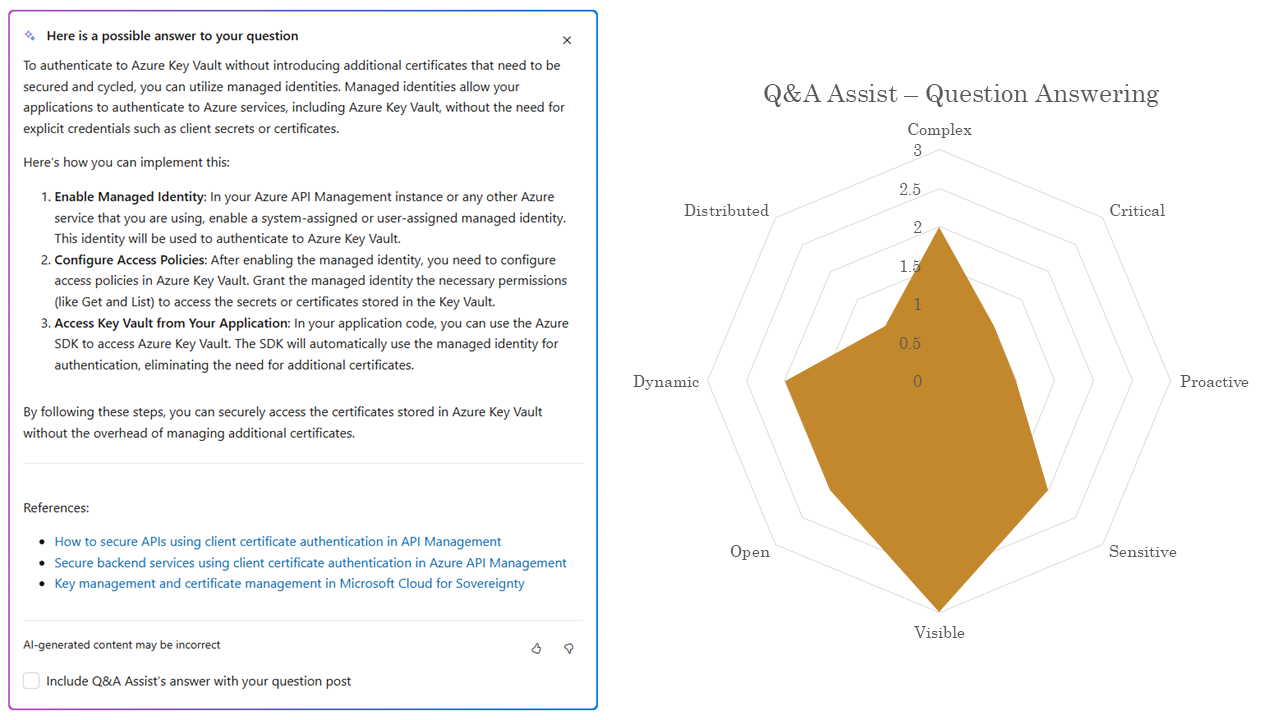 The question answering part of Q&A assist is a little bigger, it’s more dynamic, the use case may be a little more complex.
The question answering part of Q&A assist is a little bigger, it’s more dynamic, the use case may be a little more complex.
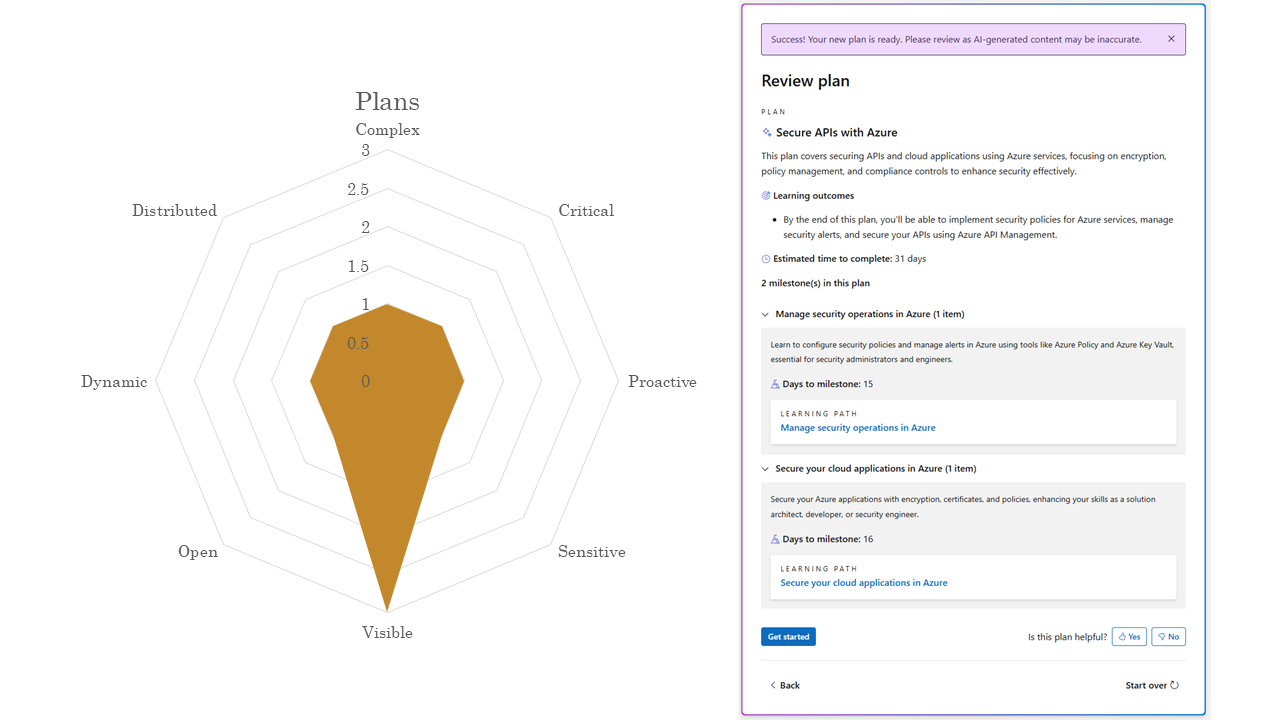 Plan generation is again, a very small footprint, besides the fact that it’s visible to users.
Plan generation is again, a very small footprint, besides the fact that it’s visible to users.
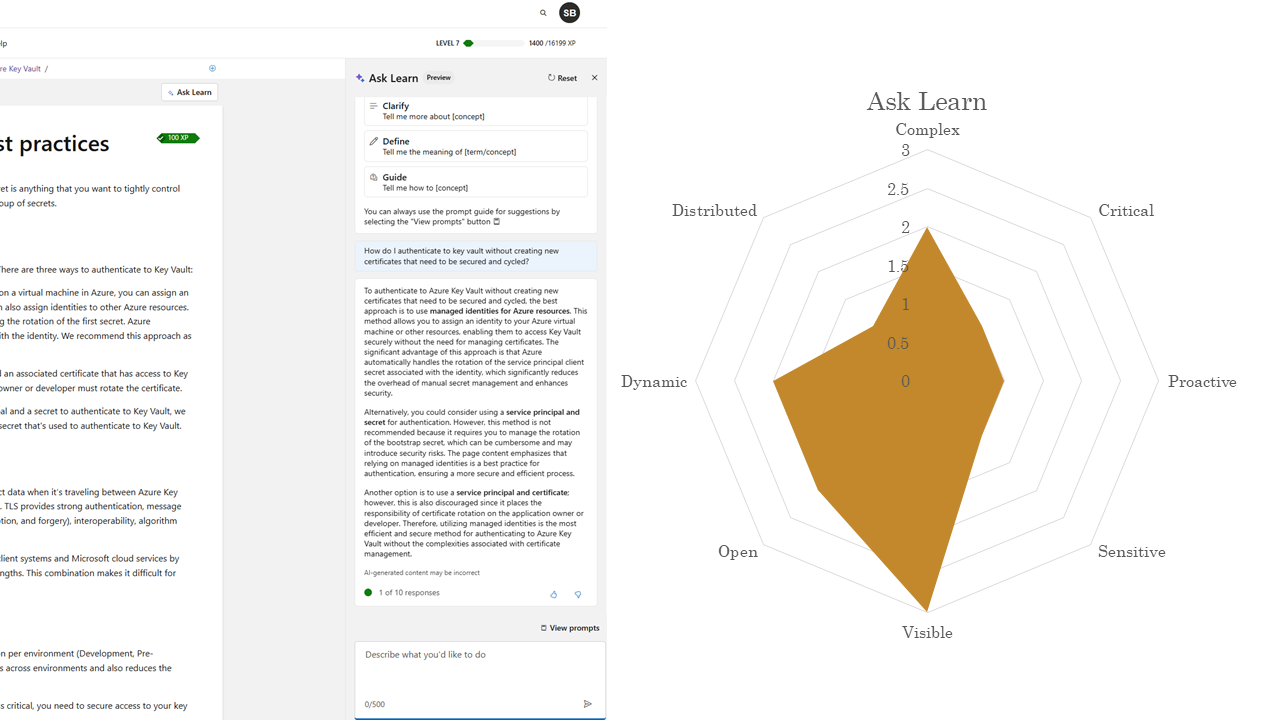 The Ask Learn assistant available on training is a little broader, more dynamic, more complex, but still reactive, targeted, and fairly closed.
The Ask Learn assistant available on training is a little broader, more dynamic, more complex, but still reactive, targeted, and fairly closed.
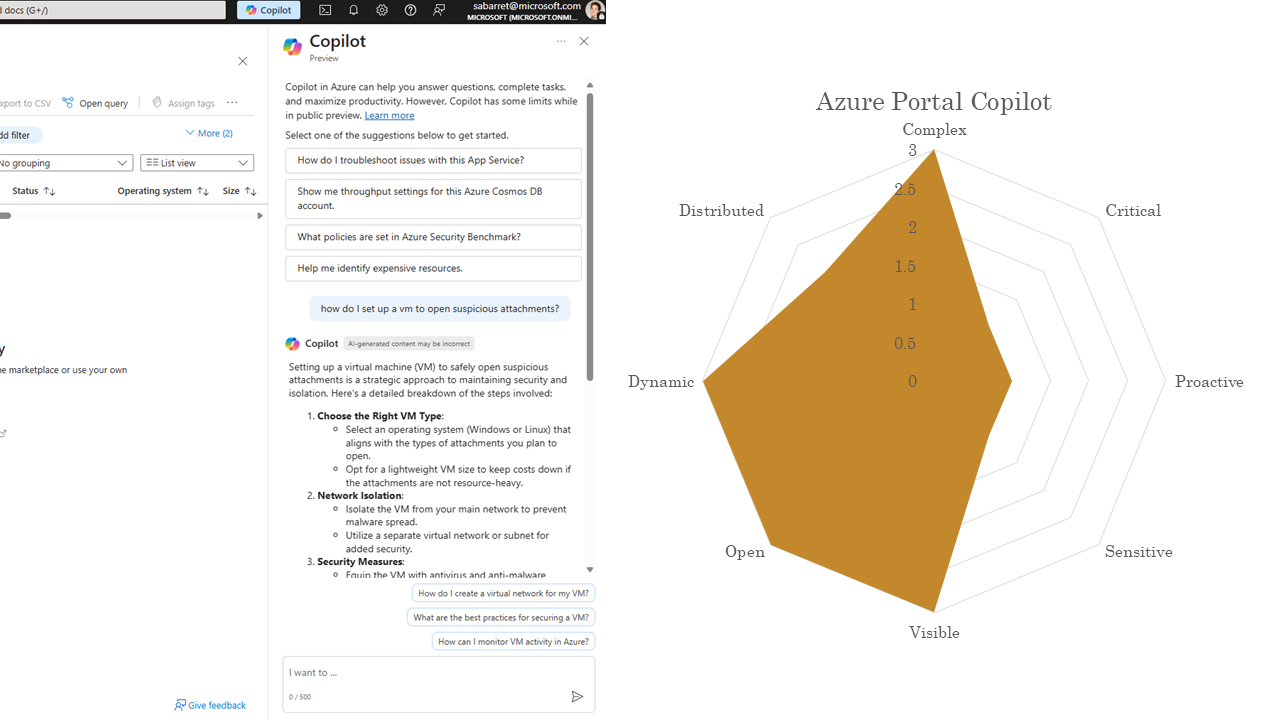 The Azure Portal Copilot isn’t an experience we build, a different team does, but we provide our data via a service to answer questions. It’s comparatively very broad.
The Azure Portal Copilot isn’t an experience we build, a different team does, but we provide our data via a service to answer questions. It’s comparatively very broad.
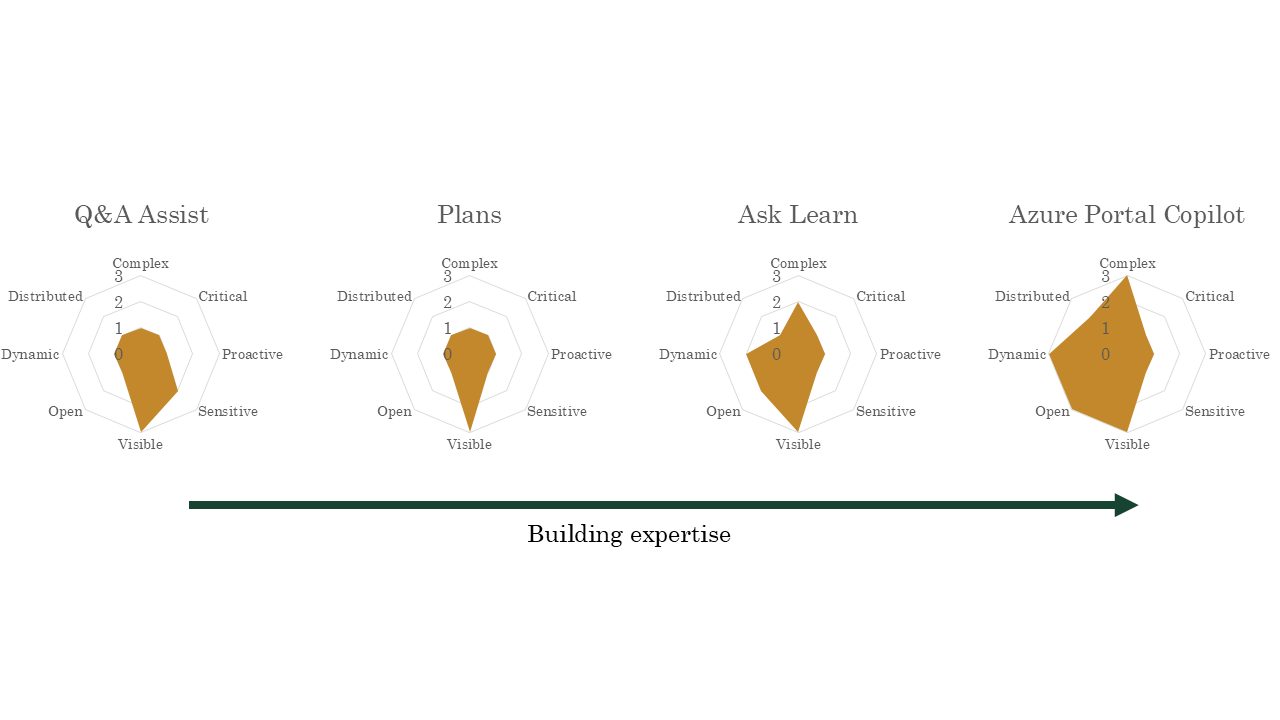 And I’m pretty sure we built them in this order. I’m talking through these not to say that we’ve done everything right, but because you can actually see how we built up to doing more complex things, we built the technical and organizational muscle to handle increased ambiguity. I think we could build more nuanced, useful, user-centered things than we have already, and I think we will.
And I’m pretty sure we built them in this order. I’m talking through these not to say that we’ve done everything right, but because you can actually see how we built up to doing more complex things, we built the technical and organizational muscle to handle increased ambiguity. I think we could build more nuanced, useful, user-centered things than we have already, and I think we will.
I know I said I wasn’t going to talk about AI ethics, but I think this matters, because a lot of the really public disasters we’ve seen in the news have been AI applications with very large ambiguity footprints launched as an organization’s first significant foray into AI. I don’t think that’s a best practice.
 I hope with the examples I’ve shown, I’ve got you thinking about more targeted and implicit, but useful and powerful applications you could build in your context.
I hope with the examples I’ve shown, I’ve got you thinking about more targeted and implicit, but useful and powerful applications you could build in your context.
References
Huyen, C. (2024). AI Engineering. O’Reilly Media. https://learning.oreilly.com/library/view/ai-engineering/9781098166298/